yolov5每次train完成(如果没有中途退出)都会在run目录下生成expX目录(X代表生成结果次数 第一次训练完成生成exp0 第二次生成exp1…以此类推)
expX目录下会保存可视化的训练结果 result.png,result.txt以及训练权重weights(last.pt和best.pt);下面简单解释一下结果参数:
1、yolov5训练结果图示
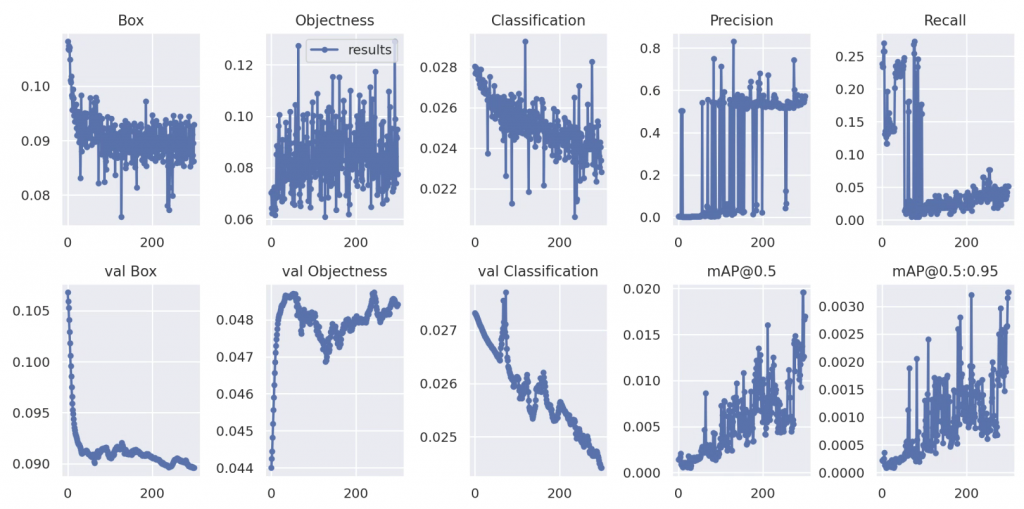
Box:YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准;
Objectness:推测为目标检测loss均值,越小目标检测越准;
Classification:推测为分类loss均值,越小分类越准;
Precision:精度(找对的正类/所有找到的正类);

翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率。两种极端情况就是,如果精度是100%,就代表所有分类器分出来的正类确实都是正类。如果精度是0%,就代表分类器分出来的正类没一个是正类。光是精度还不能衡量分类器的好坏程度,比如50个正样本和50个负样本,我的分类器把49个正样本和50个负样本都分为负样本,剩下一个正样本分为正样本,这样我的精度也是100%,但是显然这个分类器不太行。
Recall:召回率(找对的正类/所有本应该被找对的正类);

翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没一个正类被分为正类。
mAP@0.5 & mAP@0.5:0.95:就是mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。
2、result.txt解析
训练完成后生成的result.txt,我在第一列对它们进行了解释,目前还不知道最后三行是啥意思,知道的大佬可以在评论区解释一下。

转载于:https://blog.csdn.net/sinat_37322535/article/details/117260081


近期评论